Title: Spectral Bloom Filters
A Bloom Filter is a space-efficient randomized data structure allowing membership queries over sets with certain allowable errors. It is widely used in many applications which take advantage of its ability to compactly represent a set, and filter out effectively any element that does not belong to the set, with small error probability. This talk presents the Spectral Bloom Filter (SBF), an extension of the original Bloom Filter to multi-sets, allowing the filtering of elements whose multiplicities are below an arbitrary given threshold. Using memory only slightly larger than the original Bloom Filter, the SBF supports queries on the multiplicities of individual keys with a guaranteed, very small error probability. We present novel methods for lookup error minimization and an efficient data structure to build an SBF and maintain it over streaming data, as well as over materialized data with arbitrary insertions and deletions. The SBF does not assume any a priori filtering threshold; it is a high-granularity histogram, representing a high-quality synopsis for the entire dataset which allows ad-hoc queries for individual items, and enabling a range of new applications.
Title: Efficient pebbling for list traversal synopses
We show how to support efficient back traversal in a unidirectional list, using small memory and with essentially no slowdown in forward steps. Using O(log n) memory for a list of size n, the i'th back-step from the farthest point reached so far takes O(log i) time worst case, while the overhead per forward step is at most epsilon for arbitrary small constant epsilon>0. An arbitrary sequence of forward and back steps is allowed. A full trade-off between memory usage and time per backstep is presented. Our algorithm is based on a novel pebbling technique which moves pebbles on a "virtual binary tree" that can only be traversed in a pre-order fashion.
The list traversal synopsis extends to general directed graphs, and has other interesting applications, including memory efficient hash-chain implementation. Perhaps the most surprising application is in showing that for any program, arbitrary rollback steps can be efficiently supported with small overhead in memory, and marginal overhead in its ordinary execution. More concretely: Let P be a program that runs for at most T steps, using memory of size M. Then, at the cost of recording the input used by the program, and increasing the memory by a factor of O(log T) to O(M log T), the program P can be extended to support an arbitrary sequence of forward execution and rollback steps, as follows. The i'th rollback step takes O(log i) time in the worst case, while forward steps take O(1) time in the worst case, and 1+epsilon amortized time per step.
Prosenjit Bose, Evangelos Kranakis, Pat Morin, and Yihui Tang
Title: Frequency Estimation of Internet Packet Streams with Limited Space: Upper and Lower Bounds
We consider the problem of approximating the frequency of frequently occurring elements in a data stream of length n using only a memory of size m<<n. More formally, we consider packet counting algorithms that process the stream x1,...,xn of packet classes in one pass. A packet counting algorithm has a memory of fixed-size and has access to m integer counters, each of which can be labeled with a packet class. If a counter is labeled with some packet class a then we say that counter is monitoring a. While processing an item, the algorithm may modify its memory, perform equality tests on packet classes, increment or decrement counters and change the labels of counters. However, other than comparing packet classes and storing them as counter labels, the algorithm may not do any other computations on storage of packet classes. After the algorithm completes, the counter value for a packet class a is the value of the counter monitoring a. If no counter is monitoring a then the counter value for a is defined to be zero.
The problem of accurately maintaining frequency statistics in a data stream has applications in Internet routers and gateways, which must handle continuous streams of data that are much too large to store and postprocess later. As an example, to implement fairness policies one might like to ensure that no user (IP address) of a router or gateway uses more than 1% of the total available bandwidth. Keeping track of the individual usage statistics would require (at least) one counter per user and there may be tens of thousands of users. However, the results in our research imply that, using only 99 counters, we can identify a set of users, all of whom are using more than 1% of the available bandwidth and which contains every user using more than 2% of the bandwidth. If more accuracy is required, we could use 990 counters, and the threshold values become 1% and 1:1%, respectively.
Motivated mainly by applications like the one described above, there is a growing body of literature on algorithms for processing data streams [1, 3, 4, 6, 7, 9, 10, 11, 12]. An early work, particularly relevant to the current paper, is the work of Fischer and Salzberg [8] who showed that, using one counter and making one pass through a data stream, it is possible to determine a class a such that, if any element occurs more than n/2 times, then it is a. Demaine et al. [5] showed that Fischer and Salzberg's algorithm generalizes to an algorithm which they call FREQUENT. The FREQUENT algorithm uses m counters and determines a set of m candidates that contain all elements that occur more than n/(m + 1) times. Although not explicitly mentioned, it is implicit in their proof that, when FREQUENT terminates, the counter value ca for a packet class a that occurs na times obeys
In this paper we are concerned with the accuracy of packet counting algorithms. We say that a packet counting algorithm is k-accurate if, for any class a that appears na times, the algorithm terminates with a counter value ca for a that satisfies
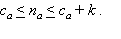
Therefore, the FREQUENT algorithm of Demaine et al. [5] is n/(m+1)-accurate. In general, no algorithm is better than n/(m+1)-accurate since, if m+1 classes each occur n/(m+1) times then one of those classes will have a counter value of 0 when the algorithm terminates.
However, this argument breaks down when we consider the case when some particular packet class
a occurs na> 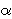 n times, for some >1/(m+1). In this case, it may be possible for the algorithm to
report the number of occurrences of a (and other elements) more accurately. We explore this relationship
between accuracy and . Our results are outlined in the next paragraph.
n times, for some >1/(m+1). In this case, it may be possible for the algorithm to
report the number of occurrences of a (and other elements) more accurately. We explore this relationship
between accuracy and . Our results are outlined in the next paragraph.
We show that the FREQUENT algorithm is (1-
REFERENCES:
Edith Cohen and Martin J. Strauss
Title: Maintaining Time-Decaying Stream Aggregates
We formalize the problem of maintaining *time-decaying*
aggregates and statistics of a data stream: the relative contribution
of each data item to the aggregate is scaled down by a factor that
depends on, and is non-decreasing with, elapsed time. Time-decaying
aggregates are used in applications where the significance of data
items decreases over time. We develop storage-efficient algorithms,
and establish upper and lower bounds. Surprisingly, even though
maintaining decayed aggregates have become a widely-used tool, our
work seems to be the first to both formally explore it and provide
storage-efficient algorithms for important families of decay functions.
Two of the most fundamental queries on a stream of values is a sum or
average. Consider a stream of nonnegative integers. It is not hard
to see that exactly maintaining the sum (or average) requires storage
of Theta( log(n)) bits (where n is the value of the sum). Work of
Morris shows how to maintain an approximate value of the sum using
only O( log log(n)) storage bits.
In many applications, however, older data items are less significant
than more recent ones, and thus should contribute less. This is
because the characteristics or ``state'' of the data generator may
change over time, and, for purposes such as prediction of future
behavior or resource allocation, the most recent behavior should be
given larger weight. A *decay*function* g(x) determines the relative
weight of each data item, as a function of elapsed time since the item
was observed. A time-decayed sum or average of the stream weighs each
item according to its elapsed time.
To date, two common decay functions have been studied: exponential
decay (g(x) = exp(-cx)) and sliding window decay (g(x) is 1 on the
window [0,W] and 0 elsewhere). As has long been known, the
exponentially-decaying weighted average can be approximately
maintained easily in a single counter, C, of log(N) bits, by the
formula C <- (1-w)x + wC, where 0 < w < 1 determines the rate of decay
and x is the new data value. Recently [DGIM] gave an efficient
algorithm for approximating sliding window decay and proved a matching
lower bound of log^2(N) bits. Here N is the age of the oldest
non-zero contribution, a parameter in common to the decay functions we
study.
We first identify some desired properties of decay functions. We then
argue, using examples, that these two families--exponential decay and
sliding windows--are insufficient: first, they do not posses some
intuitive properties, and second, they do not provide a rich-enough
class of decay rates, as the desired rate of decay for a particular
application depends on the time scales of correlations between values.
Both sliding windows and exponential decay discount older data very
dramatically. Intuitively, we expect the significance of an event to
indeed decay with elapsed time, but also to be larger for more severe
event. For different applications, we would like to be able to tune
the balance of severity with time-decay. In particular, in many
applications, we would want the relative contributions of two data
items become closer as time progresses; this is not true of sliding
window or exponential decay, but it is true of, say, polynomial decay
(g(x) = x^-alpha). Indeed, some important prediction applications
require polynomial decay and have been using expensive exact
algorithms.
As an illustrative example, consider a time-decayed aggregate of past
performance as a measure of availability of network links. We
consider two links, L1 and L2. Suppose that link L1 fails for a
5-hour duration and, 24 hours later, alternative link L2 experiences a
30-minute long failure. The two links were otherwise reliable and no
more failures are observed later on. We would like to compute online
simple numerical ratings that capture the relative reliability of the
two links. The link L1 experienced a more severe failure event than
L2, but less recently than L2. One would imagine that the initial
rating of the two links should depend on the application and the
desired balance between the severity of the failures and the 24 hours
of elapsed time. Thus, one may initially want to deem one of the
links as more reliable or deem both of them to be similarly reliable.
We would like to have a rich enough range of decay rates to support
these possibilities. Regardless of the initial rating, as time
progresses, and the time difference between the failure events become
small relative to elapsed time, we expect that L2, which experienced a
less-severe failure, to emerge eventually as more reliable than L1.
Consider first using a sliding window decay function for our two
links. A small window size would completely discount the failure
event experienced by L1, thus viewing it as a more reliable link, and
later on as an equally-reliable link. A larger window size will
provide a view that changes from one that deems L2 to be much more
reliable than L1 to one that deems L1 to be much more reliable. This
counters our intuition where we expect the relative reliability rating
of L2 to increase as time progresses. We next consider using an
Exponential decay function. Exponential decay has the property that
the relative contribution of both failure events remains fixed through
time, and, thus, its ``view'' on the relative reliability of links
remains fixed as time progresses. So depending on the decay
parameter, either L1 or L2 will be consistently viewed as the more
reliable link. Again, this view counters our intuition.
Johannes Gehrke, Cornell University
Title: Distributed Mining and Monitoring
In this talk, I will describe research problems in distributed mining.
We will first overview the basic architecture of such a system, and
then I will describe techniques for given approximate answers for
aggregate queries over data streams using probabilistic "sketches" of
the data streams that give approximate query answers with provable error
guarantees. I will introduce sketches, and then talk about two recent
technical advances, sketch partitioning and sketch sharing. In sketch
partitioning, existing statistical information about the stream is used
to significantly decrease error bounds. Sketch sharing allows to improve
the overall space utilization among multiple queries. I will conclude
with some open research problems and challenges in data stream processing.
Part of this talk describes joint work with Al Demers, Alin Dobra, and
Mirek Riedewald at Cornell and Minos Garofalakis and Rajeev Rastogi at
Lucent Bell Labs.
Irina Rish, Mark Brodie, Sheng Ma, Genady Grabarnik, Natalia Odintsova
Title: Real-time, active problem diagnosis in distributed computer systems
The rapid growth in size and complexity of today's distributed computer
systems makes performance management tasks such as problem determination
- detecting system problems, isolating their root causes and identifying
proper repair procedures - an increasingly important but also extremely
difficult task. For example, in IP network management, we would like
to quickly identify which router or link has a problem when a failure
or performance degradation occurs in the network. In the e-Commerce
context, our objective could be to trace the root-cause of unsuccessful
or slow user transactions (e.g. purchase requests sent through a web
server) in order to identify whether this is a network problem, a web or
back-end database server problem, etc. Yet another example is real-time
monitoring, diagnosis and prediction of the ''health'' of a large cluster
system containing hundreds or thousands of workstations performing
distributed computations (e.g., Linux clusters, GRID-computing systems).
Rapidly increasing complexity of distributed systems requires system
management tools that can respond both quickly and accurately to the huge
volume of real-time system measurements, and that can also actively select
and execute most-informative measurements or tests. In other words, a
''passive'' data-mining approach must be replaced by an active, real-time
information-gathering and inference system that can ''ask the right
questions at the right time''. An active, online information-gathering
approach is essential for improving cost-efficency and scalability
of real-time problem diagnosis, which is particularly important in
the context of autonomic computing, a rapidly developing area of
new-generation IT systems capable of self-management and self-repair.
We focus on real-time monitoring and diagnosis of complex distributed
computer systems based on a stream of events, such as various alarms
and systems messages, as well as response times and return codes of
test transactions called 'probes'. We are currently working on creating
a system for a real-time problem diagnosis by using probing technology
which offers the opportunity to develop an approach to diagnosis that
is more active than traditional ``passive'' event correlation [1]
and similar techniques. A probe is a command or a transaction (e.g.,
ping or traceroute command, an email message, or a web-page access
request), sent from a particular machine called a probing station to a
server or a network element in order to test a particular service (e.g.,
IP-connectivity, database- or web-access). A probe returns a set of
measurements, such as response times, status code (OK/not OK), and so on.
Examples of probing technology include the IBM T.J. Watson EPP technology
[2] and the Keynote product [3]. Probing technology is often used
to measure the quality of network performance, often motivated by the
requirements of service-level agreements (SLAs); however, using probing
for real-time problem diagnosis appears to be a relatively open area.
We approach monitoring and diagnosis in a distributed system as a
probabilistic inference problem. Indeed, in real-life scenarios fault
diagnosis involves noise and uncertainty. For example, a probe can fail
even though all the nodes it goes through are OK (e.g., due to packet
loss). Conversely, there is a chance that a probe succeeds even if a node
on its path has failed (e.g., dynamic routing may result in the probe
following a different path). Thus the task is to determine the most
likely configuration of the states of the network elements given a set of
observations such as the probe outcomes. We use the graphical framework
of Bayesian networks, where probe results correspond to observed nodes
(evidence), while the problems to be diagnosed are represented by hidden
nodes; in order to represent temporal dependencies, we extend the model
to a Dynamic Bayesian Network (i.e., 'factored' HMM model where both
hidden and observed states are multivariate).
The key efficiency issues include both the cost of probing (e.g., the
number of probes), and the computational complexity of diagnosis. Thus,
we investigate several directions towards improving the overall diagnosis
efficiency: 1) we derive some theoretical conditions on the minimum number
of probes required for an asymptotic error-free diagnosis [4], and develop
efficient search techniques for probe set selection that can greatly
reduce the probe set size while maintaining its diagnostic capability
[5,6]; 2) we propose an 'active probing' approach that allows selecting
most-informative measurements on-line to speed-up diagnosis [7,8];
3) since exact inference is often intractable in Bayesian networks,
we investigate a family of simple and efficient approximate inference
techniques based on bounded-complexity probability propagation. Our
empirical studies show that these approximations often yield an optimal
solution when dependencies are nearly deterministic, and the approximation
quality degrades gracefully with increasing 'noise'. Moreover, an analysis
provides an initial theoretical explanation of such behavior for the
simplest (greedy) approximation. See [4,9] for details.
Finally, we consider the issue of learning (or updating) a Bayesian
network given data in order to make models adaptive to intermittent
failures, dynamic routing, and other non-stationarities in the network
state and behavior. A part of our work addresses a generic problem of
choosing appropriate model-selection criteria that allow learning models
that not only fit data well, but also have other important properties
such as computational simplicity of inference [10], and sensitivity of
probabilistic query to errors in parameter estimates [11].
Xin Guo and Bonnie Ray
Title: Dynamic sampling methods in on-line process monitoring
In order to continuously monitor system performance in a dynamic
environment, it may be necessary to measure different parameter values in a
systematic manner to determine if a metric has exceeded a predetermined
threshold. This is one of the central issues in maintaining quality of
service, where the frequency and the level of ``burst'' are key
measurements. Since continuous monitoring is both expensive and
impractical, samples are taken and used to measure the performance
``approximately''. Most sampling methods determine the system status based
on a fixed threshold and a fixed sampling frequency. However, a fixed-rate
sampling method may be inappropriate, particularly when there are periodic
pattern changes in the system, for instance, bursty traffic patterns
(traffic jams) during peak hours on the internet. We propose a dynamic
sampling strategy to efficiently determine the system status while
minimizing the probability of undetected threshold crossings. We will
present some numerical results based on this methodology, as well as
investigate its performance under storage and cost constraints. As time
permits, we will also discuss some relevant on-line estimation methods for
adaptive estimation of the underlying process.
Title: Operator Scheduling for Memory Minimization in Stream Systems
In many applications involving continuous data streams, data arrival
is bursty and data rate fluctuates over time. Systems that seek
to give rapid or real-time query responses in such an environment must
be prepared to deal gracefully with bursts in data arrival without
compromising system performance. We discuss one strategy for
processing bursty streams -- adaptive, load-aware scheduling of
query operators to minimize resource consumption during times of peak
load.
During a temporary burst of greater-than-normal data arrival, the data
arrival rate may exceed the processing rate of the query processor,
necessitating the buffering of unprocessed tuples. The problem we
investigate is how best to allocate CPU cycles among query operators,
assuming query plans and operator memory allocation are fixed, in
order to minimize the backlog of unprocessed tuples that accumulate
during periods of heavy load. Our objective, the minimization of peak
memory usage, is an important one because once memory usage exceeds
the available physical memory for the system, paging to disk becomes
necessary, which is likely to cause a sudden and dramatic decrease in
system throughput. We show that the choice of an operator scheduling
policy can have significant impact on peak system memory usage, and we
present and analyze several scheduling strategies.
We have designed a scheduling policy that provably has near-optimal
maximum total memory usage. (In fact, a stronger statement is true:
our policy also has near-optimal instantaneous memory usage at every
time instant.) The policy is based on the simple observation that
executing fast, selective query operators will reduce memory usage
more quickly than executing slow, unselective operators. Our policy
sorts operators by selectivity per time unit, assigning priorities to
operators based on this metric. A straightforward greedy scheduling
policy that always schedules the highest-priority operator with
available input tuples may underutilize a high-priority operator if
the operators feeding it have low priority. Therefore, our policy
considers chains of operators within a plan when making scheduling
decisions.
We have conducted a thorough experimental evaluation to demonstrate
the potential benefit of intelligent scheduling, to compare competing
scheduling strategies, and to validate our analytical conclusions.
(Joint work with Shivnath Babu, Mayur Datar, and Rajeev Motwani)
Title: Distributed Streams Algorithms for Sliding Windows
This paper presents algorithms for estimating aggregate functions over a
"sliding window" of the N most recent data items in one or more streams.
Our results include:
Our results are obtained using a novel family of synopsis data structures
that we call "waves".
(Joint work with Srikanta Tirthapura, Iowa State)
David DeHaan, Erik D. Demaine, Lukasz Golab, Alejandro L'opez-Ortiz, and J. Ian Munro
Title: Frequent Items in Sliding Windows
Data streams share several interesting characteristics, among them
unknown or virtually unbounded length, fast arrival rate, and lack of
system control over the order in which items arrive. A particular
problem of interest concerns the statistical analysis of recent
activity on a data stream, with removal of stale items in favor of
newly arrived data. For instance, an Internet Service Provider may be
interested in monitoring streams of IP packets originating from its
clients and identifying users who consume the most bandwidth during a
given time interval. In general, queries for the most frequent items
can either ask for a list of the k most frequent items (called top-k
queries) or those items which occur above a given frequency (called
threshold queries). In network monitoring, threshold queries may be
defined with respect to the overall traffic volume. However, to make
such analysis meaningful, bandwidth-usage statistics should be kept for
only a limited amount of time (for example, one hour or a single
billable period) before being replaced with new measurements.
One solution for removing stale data is to periodically reset all
statistics. This approach gives rise to the landmark window model in
which a time point (called the landmark) is chosen and statistics are
kept only for that part of a stream which falls between the landmark
and the current time. Although simple to implement, a major
disadvantage of this model is that it does not continuously maintain
up-to-date statistics on the data stream: immediately after a
landmark, there are no reliable statistics on the current window. In
contrast, the sliding window model expires old items as new items
arrive in order to maintain a fixed window size at all times.
If the entire sliding window fits in memory, then answering threshold
Queries over the window is trivial; however, there are many
applications (e.g., monitoring Internet traffic on a high-speed link)
where the stream arrives so fast that useful sliding windows are too
large to fit in memory. In this case, the sliding window must somehow
be summarized and query results must be approximated on the basis of
the available summary information. This implies a trade-off between
accuracy and space, which is a common characteristic of on-line stream
algorithms.
In this talk, we present two algorithms for identifying frequent items
within a sliding window, for streams conforming to a stochastic stream
traffic model which assumes that the frequencies of items approximately
conform to a multinomial distribution in every instance of the sliding
window. Our algorithms extend upon the Basic Window idea of [17] and a
generalization of the algorithms introduced in [5].
A naive method for answering threshold queries is to examine all items
as they arrive and maintain a count for each item type to identify
those that appear frequently. This method takes linear space in the
worst case, when all item types are unique except for one type that
occurs twice. When adapted to the limited-memory model, this method
cannot deterministically identify all popular items, because it is
impossible to monitor every distinct item. On the other hand, random
subsampling of the data may result in large variance when the sampled
frequency is used as the estimator of the actual frequency. [6]
proposes such a sampled-counting algorithm to determine a superset
likely to contain the dominant flows.
An interesting alternative is presented in [5] where it is shown that,
using only m counters, it is possible to deterministically identify all
categories having a relative frequency above 1/(m + 1), independent of
the distribution on categories. A randomized algorithm is also
presented in [5] that finds flows with much lower frequency with high
probability, in the stochastic model mentioned above. Two similar
algorithms for answering threshold queries proposed by [15] both
identify high-frequency items and give estimates of their
multiplicities to within a factor of epsilon. An algorithm for
computing quantiles is given in [10].
We present two algorithms that build upon these results. First we
introduce an algorithm to identify the item that appears with the
highest frequency in a sliding window over a data stream composed of a
bounded set of item types, and give probabilistic estimates of the
accuracy of the prediction. Second we give an algorithm for computing
threshold queries over a data stream. We provide error estimates and
show that this algorithm outperforms straightforward random-sampling
methods.
References:
J. Feigenbaum, S. Kannan, and J. Zhang
Title: Computing Diameter in the Streaming and Sliding-Window Models
Given a set P of points, the diameter is the maximum, over all pairs x,y in P,
of the distance between x and y. There are efficient traditional algorithms
to compute the exact diameter [5, 11] and to approximate the diameter [1, 2, 3].
We investigate the 2-d diameter problem in the streaming model [7, 8] and
the sliding-window model [6].
Sliding-window versions of problems have much in common with dynamic versions,
which have long been studied in computational geometry [9, 10, 4].
In a "dynamic" problem, the input data set is not fixed; rather, data
elements can be added or deleted as the algorithm proceeds. Most known
algorithms for dynamic problems in computational geometry use data structures
that support efficient updating and query-answering. These data structures
may contain all of the data elements currently under consideration; thus they
cannot be used in the streaming or sliding-window models, where space
complexity must be sublinear (in the stream size or window size).
For a set of n points, we show that computing the exact diameter in the
streaming model or maintaining it in the sliding-window model require
Omega(n) bits of space. We present an epsilon-approximation algorithm in
the streaming model that requires space to store O(1/epsilon) points and
processing time O(1) for each point. We also present an epsilon-approximation
algorithm that maintains the diameter in the sliding-window model, using
O((1/epsilon)^(3/2)*log^3n(log R + loglog n + log 1/epsilon))
bits of space, where R is the maximum, over all windows, of the ratio
of the diameter to the non-zero minimum distance between any two points in
the window.
Our approximation is based on a well-known diameter approximation
algorithm. It is easy to maintain the diameter for a 1-d point set when
points can be added but not deleted as the algorithm proceeds, which is
precisely what happens in the streaming model. In the 2-d case, the
approximation projects the points in the plane onto a set of lines and
computes the diameters for each of the lines. The maximum of all the line
diameters is used as the approximation. To process each point, the algorithm
needs to project the point onto each line and thus takes O(1/sqrt{epsilon})
time. Instead of using lines, our diameter-approximation algorithm in the
streaming model divides the plane into sectors. It's processing time
for each point is O(1).
The above approximation algorithms fail when deletions are allowed as well as
additions, as they are in the sliding-window model. We can still use the
technique of projecting the points onto a set of lines, but we cannot simply
maintain the extreme points for each line as we do in the streaming model,
because these extreme points may be deleted in the future. Instead, in
the sliding-window model, we group the points into clusters and reduce the
number of points in a cluster by "merging" two points that may be close to
each other. The current window is divided into multiple clusters, and they
are updated as the window slides. The diameter of the current window can be
approximated from the diameters of the clusters. This requires amortized
processing time O(log n) for each point. The worst-case processing time is
O((1/epsilon)^(3/2)*log^2n(log R + loglog n + log 1/epsilon)) for each
point.
In the statements of these results, we have used the additional parameter R.
In fact, we show that the space complexity of maintaining the diameter is
closely related to R. For huge R, i.e., R > 2^n , our sliding-window
algorithm may take space larger than n. However, Omega(n) is a lower bound
on the space complexity in this case. In fact, for R > 2^n , our
sliding-window approximation can be viewed as a tradition algorithm for
dynamic diameter problem.
These results represent further development of the work presented by Kannan
at the 2001 meeting of the DIMACS Working Group on streaming data analysis.
References:
Title: Streaming Algorithms in Graphics Hardware
The computing industry is seeing the emergence of a powerful subsystem:
the graphics accelerator card. This subsystem, capable of rendering
millions of objects per second, demonstrates parallelism in pixel-level
rendering and is based on a architecture designed for processing data
streams. Moreover, it is now undergoing powerful augmentation with
the introduction of programmability in its traditionally fixed pipeline
architecture. These graphics accelerator cards are inexpensive and
ubiquitous (most off-the-shelf PCs have them, as do all video game
consoles), and essentially provide an alternative computational platform
for the interactive visualization of streams. Graphics hardware has been
already used to accelerate computation of general interest in data
analysis, GIS, geometry and graphics, These algorithms provide
proof-of-concept; however, they have only used a small subset of the
capabilities that current hardware provides, and exclude all of the
programmable aspects.
What is the extent of the capabilities of the graphics pipeline ? To
answer this question, we need to understand the computational power that
it provides. As a model of computing, the pipeline draws together ideas
from streaming algorithms, parallel computing, and approximation
algorithms. A formal investigation of this will both tell us what we can
do with graphics cards, and how we can improve them in the future.
In this talk, I will survey the streaming computing capabilities of the
graphics pipeline, and present some examples of problems that can
currently be solved using the graphics pipeline.
Nat Duca, Jonathan Cohen, Peter Kirchner
Title: Stream Caching: A Mechanism to Support Multi-Record Computations within a Stream Processing Architectures
One of the basic ideas of stream processing is that, as data sizes
grow larger, it becomes more efficient to process data in a streaming,
rather than random access, fashion. One of the primary gains in doing
so is that streaming algorithms give rise to predictable data access
patterns, requiring a less advanced memory hierarchy and ultimately
allowing more resources to be devoted to the actual computation
process. The downside of streaming algorithms - at a very practical
level - is that, because random access is no longer available to the
programmer, the classes of problems that can be solved by the system
becomes significantly smaller. We discuss an addition to the standard
record-oriented stream processing model called Stream Caching which
allows limited random access and multi-record computations to occur
within a stream processing framework. We suspect, based on our
experience within the graphics area, that stream caches greatly expand
the capabilities of stream-processing --- to what extent, however,
is an open question which we would very much like to discuss.
Our perspective on this work is graphics stream processing. Of
particular interest to us is the idea of using streaming algorithms to
unify a cluster of workstations as a single visualization
cluster. Early work in this area focused on the basic algorithms for
achieving this [Humphreys01]. More recently, efforts have focused on
the support framework for the algorithms; the Chromium software
[Humphreys02] provides an advanced framework to build and experiment
with stream processing algorithms for graphics streams. One of the big
limiting factors in the application of stream processing to graphics
is its inefficiency with bandwidth. It is a well understood fact that
graphics streams are highly repetitive: the need for scenes to appear
similar across multiple frames gives rise to natural temporal
coherence in frames. It has been commented in the literature that
processing of graphics streams must include a caching mechanism
(e.g. display list support) to store repetitive parts of a stream
within the pipeline [Humphreys99]. We recently presented a series of
modifications to Chromium [Duca02] that addresses this issue by
automatically finding and properly caching repetitions in an OpenGL
command stream. We do this using stream cache, which is derived as a
convenient solution for achieving other graphics-oriented goals. The
intent of this work is to extract the stream cache technology from our
previous work and present it as a technology not explicitly linked
with graphics and visualization.
Stream caching consists of two simple changes to the standard stream
processing model. First, the stream format is changed to include two
extra record types, CACHE_BEGIN and CACHE_END, which are then placed
into the stream in such a way that all the records between the two
become a special "stream cached region". Second, the code that handles
transport of records between different SPUs is modified in the
following way: when a CACHE_BEGIN record is received, all subsequent
records enter a large memory buffer and are not operated on. When
CACHE_END is received, the entire buffer is handed off to a cache
processing function. In practice, this process - the "caching process"
- is enabled by the SPU configuration framework only on a limited
number of SPUs in order to control and produce a variety of different
types of computation models.
The effect of these modifications is best illustrated in the following
example. A standard stream processing function is kernel-like
This new function allows a stream processing unit to perform
computations on
multiple records. The benefits of this are best explained by
enumerating the functional capability of stream processing units with
and without caching:
An important argument remains to be made, however: do the memory
requirements of a stream cache nullify the benefits gained with a
stream processing approach? The issue here is that stream processing
access patterns are predictable, and require little memory management
to function, leading to chip real-estate savings in the hardware
world, which is what makes the whole system appealing. Stream caching
appears to bring random-access back into the picture, threatening the
return of random access memory and all of the complexities that it
entails. The first impression one has is that, yes, stream caches
break all of the savings ordinarily to made with streaming algorithms.
We know this to be true if we, in the style of scalar architectures,
support unlimited stream cache sizes, which amounts to supporting
fully scalar computation within a streaming framework. However, the
strength of stream caches is that they can easily be finite in size
without damaging their overall functionality. Indeed, the maximum size
of a stream cache supported by a framework can be easily determined as
a cost benefit analysis of memory requirements against programmability
gains. In other words, for a given supported size, stream caching is
quite feasible. Interestingly, in the software stream processing
world, the only case against supporting stream caches is the cost
of buffer packing. To this end, we have demonstrated in our Chromium
implementation of stream caches that even this hurdle can be
overcome given proper design choices.
Are stream caches simply a scalar CPU pretending to support streaming
functionality? We think not. On the contrary, stream caches provide a
way to perform limited scalar computations within a stream processing
framework. What algorithms can be produced within this expanded
architecture? We have, in previous work, shown that a wide variety of
graphics operations are possible using stream caches that are not
possible in standard stream processing. To name a few, we have
described systems for bandwidth optimization, distributed tilesort,
in-driver Level of Detail, latency-safe rendering, and perhaps even
in-driver stylistic rendering. Conceptually, however, we see no reason
or evidence to suggest that stream caches are useful exclusively for the
graphics field. Whether and what uses of stream caching has in a broader
field seems to be a wide open question which we area eager to pose to
the stream processing community as a whole.
Title: Streaming and Pseudorandom Generation
Consider a sketch-based algorithm for streaming that constructs a sketch
of the input and then uses the sketch to compute the answer,
the difference of Lp norms, for instance. In this case the sketch is
is really used only once, at the end to compute the difference. Recently
we are seeing algorithms that are more involved, for instance to compute
the best k-term wavelet representation we may try to extract the best
1-term approximation using the sketch (achieved some efficient seatching
over the space of possible 1-term wavelets and by minimizing L2 norm of
difference) -- and then we may try to update the sketch and try to find
the solution in a greedy recursive way.
The above is just an example where we re-use the sketch significantly.
There are other more nvolved examples. A problem that arises in this
context is of correctness. Notice that a sketch is accessed multiple times
and thus simulation by pseudorandom generators is non-trivial.
Alternately we may use sketches generated from codes, but in either case
we have to prove for each algorithm "this algorithm is correct".
A natural question is that can a black box proof be given such that if we
construct sketches in a particular fashion, and access the sketch a small
(polylog) number of times then there always exists a small-space
pseudorandom simulation which proves the computation is correct ? This
would require us to create sketches more carefully, and formalize what
sketch accesses are allowed. We answer this question in the affirmative,
under natural (includes all known ways) ways of accessing the random bits
used for the sketch construction. What this achieves is a black box proof
of correctness for small-space polylog time sketch algorithms, even when
the sketch is reused many times.
Title: Inferring mixtures of Markov chains
We define the problem of inferring a ``mixture of Markov chains'' based
on observing a stream of interleaved outputs from these Markov chains.
Several variants are possible. In the first one we consider, the mixing
process chooses one of the Markov chains independently according to a
fixed set of probabilities at each point, and only that chain makes a
transition and outputs its new state. For this case, when the individual
Markov chains have disjoint state sets we show that a polynomially-long
(in the size of the state space) stream of observations is sufficient to
infer arbitrarily good approximations to the correct chains. We also
explore a generalization where the mixing probabilities are determined
by the last output state. When the state sets are not disjoint, for the
case of two Markov chains, we show how we can infer them under a
technical condition.
We also consider a related model where the output function of the states
is not a one-to-one mapping as above. We explore some inference problems
on such Markov chains. For example, a basic question we can ask in this
model is under which circumstances is the observed behavior of such a
chain itself a Markov chain.
We believe that the problems we consider are of independent theoretical
interest, but we are also motivated by applications such as gene finding
and intrusion detection, and more generally, the goal of formalizing an
important subclass of data mining problems.
Joint work with Sudipto Guha and Sampath Kannan.
Matthias Ruhl, Gagan Aggarwal, Mayur Datar, and Sridhar Rajagopalan
Title: Extending the Streaming Model: Sorting and Streaming Networks
The need to deal with massive data sets in many practical applications has led to a growing interest in
computational models appropriate for large inputs. One such model is ``streaming computations'' [MP80,
AMS99, HRR99], where inputs are provided as a long sequence of data items. In this model, functions are
computed by a machine with small local memory making one or a small number of linear passes on the input
stream. In this talk, motivated by practical considerations, we discuss two extensions of this computational
model. Despite being quite different in motivation and form, these extensions turn out to be closely related
in their computational power. This suggests that the computational class defined by them is somewhat stable
and deserves further study.
Streaming and Sorting. The first extension is motivated by two facts about modern computing platforms.
First, storage on disk is readily available and cheap (in the order of a few dollars per gigabyte). This implies
that large amounts of temporary storage can, and should, be used, suggesting that the classical streaming
model may be too restrictive in not allowing data storage at intermediate stages of the computation.
Second, sorting a large collection of fixed size records can be done extremely efficiently on commodity
hardware, with rates that bottleneck the I/O subsystem (see for instance [Aga96, ADADC+97, Wyl99, Cha09])
This contrasts with the fact that sorting is formally hard in streaming models. This seems to
suggest that the formal streaming models are overly pessimistic in modeling the capabilities of today's computing
platforms. If we assume that sorting is possible, i.e. we enhance the classical streaming model by
providing a ``sort box'', then clearly the class of problems solvable by this ``streaming and sorting model'' is
strictly larger than that solvable in the classical streaming model.
We formalize this model and show that it admits efficient solutions to a number of natural problems, such
as undirected connectivity, minimum spanning trees, suffix array construction, and even some geometric
problems. These problems are all known to be hard in the streaming model, suggesting that the addition of
a sorting operation extends that model in a meaningful way.
To show the limits of this model, we state a function that cannot be computed efficiently in it, but allows
for a simple computation by a machine that is allowed to read two streams in parallel.
Streaming Networks. Recent networking applications, such as the Chromium project [HEB+01, HHN+02]
for distributed graphics rendering, use streams to exchange data in a network. The topology of such a network
can be modeled as a directed acyclic graph. A node in the graph represents a machine with small local
memory, and edges are streams transmitted between nodes. Each node reads the streams given by the edges
pointing to it, and writes output streams for the edges leaving from it. We formalize this model, and address
the question of its computational power.
It turns out that its capabilities depend heavily on the way in which the nodes can access their input
streams. Forced to read them one after another in their entirety, the model becomes equivalent to the
``streaming and sorting'' model mentioned above. Allowed to freely interleave accesses to input streams, the
network's computational power increases dramatically. We show corresponding equivalences and separations.
During the course of the talk we will formalize the different models and present results of the form: A
streaming algorithm with access to a ``sort box'', and using memory m is no more powerful than an external
memory algorithm that uses O(1) disks, requires main memory m and makes O(log n)
``out-of-sequence'' reads for each pass of the streaming algorithm.
More details can be found in the full version of this work [RADR].
References:
Moses Charikar, Liadan O'Callaghan, and Rina Panigrahy
Title: Better Streaming Algorithms for Clustering Problems
In recent years, there has been great interest in
computation on massive data sets. In particular, the
streaming model [2, 9] has received much attention.
In this model, an algorithm can only make one scan
(or a small number of scans) over its input, using
limited memory. This model is commonly used for
settings where the input size far exceeds the amount
of main memory available, and the data is only accessible
via linear scans, each of which is expensive.
Here, we examine stream clustering problems.
Clustering has been studied extensively across several
disciplines and is typically formulated as an optimization
problem, where the input is a set of points
with a distance function and the goal is to find a clustering
(a partion into clusters) that optimizes a certain
objective function. A common such function is the
k-Median objective [8]: find k points (medians) in a
set of n points so as to minimize the sum of distances
of points to their closest centers. There is extensive
research on this problem and related problems
[5, 11, 3, 17, 13, 16]. Another objective is k-Center,
where the goal is to find k centers that minimize the
maximum distance of a point to its closest center; this
problem has a 2-approximation, which is tight [10].
Intuitively, a stream clustering algorithm that
maintains a small amount of state must maintain
a succinct representation of the clustering solution
(usually just the set of cluster centers plus some additional
information), and an implicit lower bound on
the cost of the optimal solution for the sequence seen
so far. Thus it appears that any clustering objective
function that admits such a clustering algorithm must
have succinct lower bound certificates. For the
k-Center objective, such a certificate follows directly
from the analysis of the offline k-Center problem.
While the best-known streaming algorithm for
k-Center [4] uses only O(k) space and yeilds an
O(1)-approximation, the currently best known streaming
algorithm for k-Median requires O(n
Our Results: Our main result, which solves this open
problem from [7], is a streaming k-Median algorithm
that uses O (k poly log n) space and produces
an O (1)-approximation; the algorithm is randomized
and works with high probability. Our algorithm
can be summarized as follows: We obtain a clustering
solution with k log n medians which is only a
constant factor worse than the optimal (with k medians).
The final medians are obtained by solving
a k-Median problem on these O (k log n) medians
(appropriately weighted). The crux of our approach
is maintaining a constant-factor-approximate solution
using k log n medians and using O (k poly log n)
space in the streaming model. Our algorithm operates
in phases, each of which uses the recent online
facility location algorithm by Meyerson [14], and our
lower bound on the optimal cost is updated between
phases.
Next, we study the k-Median problem with an
arbitrary distance function. Given an upper bound
We also study outlier formulations of stream clustering
problems: For a given parameter 0 <
1 For k-Median with outliers, even in the offline setting, it
is not known how to obtain a solution with a constant factor
approximation while maintaining the same fraction of outliers as
the optimal solution.
References:
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S. Mirrokni
Title: Locality-Sensitive Hashing Scheme Based on p-Stable Distributions
Title: On the Optimality of the Holistic Twig Join Algorithm
)n/m-accurate, where n
is the number of times
the most frequently occurring packet class appears in the stream. We also give a lower-bound of
(1-)n/(m+1) on the accuracy of any deterministic packet counting algorithm, which implies the
FREQUENT algorithm is nearly optimal. Finally, we show that randomized algorithms can not be significantly
more accurate since there is a lower bound of (1-
This talk will be theoretical, non-experimental, and accessible to
practitioners. Example applications will be discussed.
[Rixner01], e.g.:
spuRecordHandler(record r) {
... modify r, pass it downstream to > 1 SPU,
create some new records, etc ...
}
Stream caching makes the following new multi-kernel computation
possible:
spuCacheHandler(records* r, int num_records)
* Standard SPUs are capable of only two types of records in-to-out
ratios: 1:1 or 1:n. This is understood to limit the problems that
the system can solve.
* A stream-cached SPU is capable of an additional two
behaviors: n:1, n:m. Our argument, made here only informally, is
that this allows a whole new range of computations to be
performed while still preserving the essential elements of stream
processing architectures.
[Duca02] N. Duca, P.D. Kirchner, and J.T. Klosowski. Stream Caches:
Optimizing Data Flow in Visualization Clusters. Commodity
Cluster Visualization Workshop, IEEE Visualization
2022. Available at http://duca.acm.jhu.edu/research.php.
[Humphreys99] G. Humphreys, P. Hanrahan. A Distributed Graphics System
for Large Tiled Displays. In Proc. IEEE Viz 1999.
[Humphreys01] G. Humphreys, M. Eldridge, I. Buck, G. Stoll,
M. Everett, and P. Hanrahan. WireGL: a Scalable Gaphics
System for Clusters. In Proc. SIGGRAPH 2001.
[Humphreys02] G. Humphreys, M. Houston, R. Ng, R. Frank, S. Ahern,
P.D. Kirchner and J.T. Klosowski. Chromium: A stream
processing framework for interactive rendering on
clusters. In Proc. SIGGRAPH 2002.
[Rixner01] S. Rixner. A Bandwidth-efficient Architecture for a
Streaming Media Processor. PhD. Thesis. Massachusetts
Institute of Technology, 2001.
 ) space and
produces 2O(1/
) space and
produces 2O(1/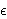 ) approximation [7]. Our research
was motivated by the following question, left open
by Guha et al. : Is there a streaming algorithm for
k-Median that uses only O (k poly log (n)) space and
produces a constant (or even logarithmic) approximation
factor?
) approximation [7]. Our research
was motivated by the following question, left open
by Guha et al. : Is there a streaming algorithm for
k-Median that uses only O (k poly log (n)) space and
produces a constant (or even logarithmic) approximation
factor?
 on the ratio of the maximum distance to the minimum
distance, we give a streaming algorithm that makes
O (log ) passes and uses
space O(k2 log /2 ) to
produce a solution which is a (1 + )-approximation
using O (k log)/) centers. We note that Young
[18] gave a greedy algorithm that produces a (1 + )
approximation using ln (n + n/)k centers, and that,
as shown by Lin and Vitter [12] an O (log n) increase
in the number of centers is inevitable for this problem.
on the ratio of the maximum distance to the minimum
distance, we give a streaming algorithm that makes
O (log ) passes and uses
space O(k2 log /2 ) to
produce a solution which is a (1 + )-approximation
using O (k log)/) centers. We note that Young
[18] gave a greedy algorithm that produces a (1 + )
approximation using ln (n + n/)k centers, and that,
as shown by Lin and Vitter [12] an O (log n) increase
in the number of centers is inevitable for this problem.
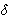 < 1,
find a solution that clusters at least (1 - ) fraction
of the points and optimizes the objective function
on these chosen points. (In other words, we are allowed
to exclude at most fraction of the points, or
``outliers,'' from the clustering). Charikar et al. [6] recently
introduced these outlier formulations and gave
O(1)-algorithms for the outlier versions of k-Center
and k-Median. We obtain O(1)-approximations for
these problems on streams, that use O(k log n) space
and slightly increase the outlier fraction (a bicriterion
guarantee). 1 Our algorithms for these problems are
extremely simple and very efficient when viewed as
offline algorithms. We show that for both of these
problems, solving an outlier clustering problem on a
random sample of size O (k log n) gives a good solution
for the entire data set. In either case, we obtain an
implicit representation for the solution in the form of
k cluster centers and a distance threshold; the points
that have no cluster center within the distance threshold
are considered outliers, and the rest are assigned
to their closest centers. These results are related to
those obtained by Alon et al. [1] and Meyerson et al.
[15], although those works use different algorithmic
techniques and assume a different input model. Other
sampling-based k-Median algorithms include those
of Thorup [17], Mettu and Plaxton [13], and Mishra
et al. [16].
< 1,
find a solution that clusters at least (1 - ) fraction
of the points and optimizes the objective function
on these chosen points. (In other words, we are allowed
to exclude at most fraction of the points, or
``outliers,'' from the clustering). Charikar et al. [6] recently
introduced these outlier formulations and gave
O(1)-algorithms for the outlier versions of k-Center
and k-Median. We obtain O(1)-approximations for
these problems on streams, that use O(k log n) space
and slightly increase the outlier fraction (a bicriterion
guarantee). 1 Our algorithms for these problems are
extremely simple and very efficient when viewed as
offline algorithms. We show that for both of these
problems, solving an outlier clustering problem on a
random sample of size O (k log n) gives a good solution
for the entire data set. In either case, we obtain an
implicit representation for the solution in the form of
k cluster centers and a distance threshold; the points
that have no cluster center within the distance threshold
are considered outliers, and the rest are assigned
to their closest centers. These results are related to
those obtained by Alon et al. [1] and Meyerson et al.
[15], although those works use different algorithmic
techniques and assume a different input model. Other
sampling-based k-Median algorithms include those
of Thorup [17], Mettu and Plaxton [13], and Mishra
et al. [16].
approximations with
minimum packing constraint violation. Proc. 24th
STOC, pp. 771-782, 1992.



