While Corollary 3 proves the decidability of determining if ![]() , it is an extremely inefficient algorithm. In
particular, enumerating all sequences of expanding rules of length
, it is an extremely inefficient algorithm. In
particular, enumerating all sequences of expanding rules of length
![]() will yield exponential complexity. In practice however, we
can search for a derivation of x from
will yield exponential complexity. In practice however, we
can search for a derivation of x from ![]() by using the structure
of x . Specifically, we have the following theorems:
by using the structure
of x . Specifically, we have the following theorems:
Theorem 4: ![]() if and only
if
if and only
if ![]() or
or ![]() and
and ![]() .
.
Proof: Assume ![]() and
and
![]() , then
, then ![]() must be
in
must be
in ![]() because of an expanding rule. By assumption,
because of an expanding rule. By assumption,
![]() . To show that
. To show that ![]() can be derived from
can be derived from ![]() without using a shrinking
rule we take a derivation of
without using a shrinking
rule we take a derivation of ![]() ,
,![]() , and use theorem 2 to get a normalized derivation
, and use theorem 2 to get a normalized derivation ![]() .Now either the shrinking rules appearing in
.Now either the shrinking rules appearing in ![]() are redundant
(i.e. they don't add any new words and so can be removed from the
derivation) or we contradict the fact that
are redundant
(i.e. they don't add any new words and so can be removed from the
derivation) or we contradict the fact that ![]() was created by
applying all possible shrinking rules to B . In either case the
remainder of the derivation (and there must be some remainder since we
assume that
was created by
applying all possible shrinking rules to B . In either case the
remainder of the derivation (and there must be some remainder since we
assume that ![]() ) must consist of
expanding rules. In particular the last rule used in the derivation
must be an expanding rule and the only way that could be the case is
if it is rule 2 which would require as its premise
) must consist of
expanding rules. In particular the last rule used in the derivation
must be an expanding rule and the only way that could be the case is
if it is rule 2 which would require as its premise ![]() and
and ![]() .
.
Now assume that ![]() or
or ![]() and
and ![]() . Then it is clear
by either rule 1 or rule 2 that
. Then it is clear
by either rule 1 or rule 2 that ![]() .
.
Theorem 5: ![]() if and only if
if and only if ![]() or
or ![]() and
and ![]() .
.
Proof: Analogous to the previous theorem.
Putting all these together yields the basis for our search algorithm.
As our set of known messages increases, we repeatedly apply shrinking
rules and removing ``redundant messages'' until we get a set of
``basic'' messages, ![]() , to which we cannot apply any shrinking
rules. By redundant messages, we mean messages that can be generated
from the other messages in the set using expanding rules. For
example, when we apply rule 3 to get
, to which we cannot apply any shrinking
rules. By redundant messages, we mean messages that can be generated
from the other messages in the set using expanding rules. For
example, when we apply rule 3 to get ![]() and
and ![]() from
from ![]() , we also remove
, we also remove ![]() from
from ![]() .However, when applying rule 5 we must be careful; when we generate m
from
.However, when applying rule 5 we must be careful; when we generate m
from ![]() and
and ![]() we cannot remove
we cannot remove ![]() from
from
![]() unless
unless ![]() . Pseudocode for this algorithm is given
in figure 2.
. Pseudocode for this algorithm is given
in figure 2.
Figure 2:
Augmenting the intruder's knowledge
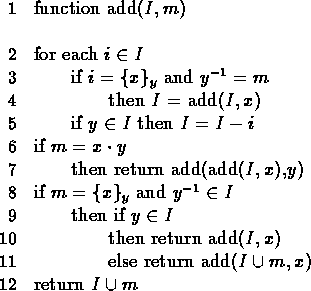
We now consider the complexity of inserting a new message m into our
current set of information ![]() and generate a new set of
information
and generate a new set of
information ![]() . The only time there is any interaction between
previously known messages in
. The only time there is any interaction between
previously known messages in ![]() and m is when we try to apply
the decryption rule. The message m can have at most |m|
encryptions. For each encryption, we scan
and m is when we try to apply
the decryption rule. The message m can have at most |m|
encryptions. For each encryption, we scan ![]() looking for the
inverse key for a total of
looking for the
inverse key for a total of ![]() time. Analogously, m could
contain at most |m| keys. For each key, we must check each element
of
time. Analogously, m could
contain at most |m| keys. For each key, we must check each element
of ![]() to see if it can now be decrypted. Again, this takes at
most
to see if it can now be decrypted. Again, this takes at
most ![]() time. However, the newly decrypted message could
again be decrypted. The number of iterations is bounded by
time. However, the newly decrypted message could
again be decrypted. The number of iterations is bounded by ![]() ;therefore, the total time to generate
;therefore, the total time to generate ![]() , is bounded by
, is bounded by
![]() and the size of
and the size of ![]() is bounded by
is bounded by ![]() .
.
We know that any words in ![]() can be derived using only
expanding rules. When we search to see if a word w is known, we can
use theorems 4 and 5 to break it down into smaller pieces which can
then be searched recursively. For example, if
can be derived using only
expanding rules. When we search to see if a word w is known, we can
use theorems 4 and 5 to break it down into smaller pieces which can
then be searched recursively. For example, if ![]() , then theorem 5 tells us that
, then theorem 5 tells us that ![]() only if
only if
![]() .Pseudocode for this algorithm is given in
figure 3.
.Pseudocode for this algorithm is given in
figure 3.
Figure 3:
Searching the intruder's knowledge

When searching for a derivation of w from ![]() we first check to
see if
we first check to
see if ![]() . This costs at most
. This costs at most ![]() time. If not, we
break down w into two smaller pieces and recursively check those
peices. The total number of recursive calls is bounded by the number
of operations making up w , which is in turn bounded by |w| . Thus
the total time to check if
time. If not, we
break down w into two smaller pieces and recursively check those
peices. The total number of recursive calls is bounded by the number
of operations making up w , which is in turn bounded by |w| . Thus
the total time to check if ![]() is bounded by
is bounded by
![]() .
.